Logistic-Regression-on-MNIST-dataset
目标:实现逻辑回归算法,并在MNIST数据集中查看学习器的效果。
Minist数据集
数据类别:手写数字数据集,有0~9这十个类别。每张图片是$28\times28\times1$的灰度图像。
数据集规模:训练集为60000个样本,测试集为10000个样本。
由于有10个类,可以采用OvR的多分类处理,也可以采用EOCO编码来做MvM。
逻辑回归实现
逻辑回归模型
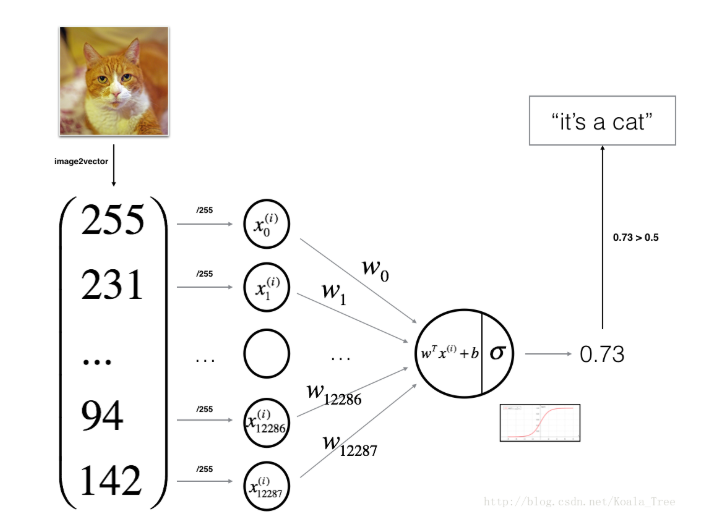
逻辑回归算是个采用Sigmoid激活函数的神经网络单元了。
对于一个样例$\boldsymbol{x}_i$:
我们的模型包含两部分:线性部分和激活函数:
若$\hat{y}_i\leq0.5$,则为反例;若$\hat{y}_i>0.5$,则为正例。
$\hat{y}$可视该样例属于正类的概率。
损失函数
单个变量$\boldsymbol{x}_i$损失函数为(对数似然):
当$y_i=0$时,即$\boldsymbol{x}_i$属于反类,对数损失为$\ln(1-\hat{y}_i)$;
当$y_i=1$时,即$\boldsymbol{x}_i$属于正类,对数损失为$\ln\hat{y}_i$。
对于所有训练样本的损失函数为
现在我们要的参数$(\boldsymbol{w}^{*},b^{*})$要满足
梯度下降
目的是:寻找最优参数$\boldsymbol{w}^{*}$和$b^{*}$,使得我们的目标函数$J$最小。
- 初始化$\boldsymbol{w},b$为零
对数函数是一个凸函数,初始化为任意值都可通过梯度下降找到最优解。
1 | w = np.zeros((X_train.shape[0], 1)) |
进行num_iterations次梯度下降:
- 用当前的$\boldsymbol{w}$和$b$计算$\hat{\boldsymbol{y}}$
1 | # 首先求出线性部分和激活函数 |
- 计算损失函数:
1 | # 计算损失函数 |
- 计算损失函数对w和b的偏导数
1 | # 求梯度 |
- 梯度下降获得新的w,b
1 | # 梯度下降 |
经过num_iterations次梯度下降就得到我们最后的$\boldsymbol{w}^{*}$和$b^{*}$了。
(当然不一定是完全收敛好的解,这些还需要我们去挑一些参数。)
将$\boldsymbol{w}^{*}$和$b^{*}$带入,就得到我们模型的最终的$\hat{\boldsymbol{y}}$
1 | # 训练集上的predict y_hat |
$\hat{\boldsymbol{y}}$算是属于正类的概率。
根据我们的阈值0.5,可以进一步的到最终的预测值(1表示正类,0表示反类)
1 | y_prediction_train = np.zeros((1, m_train)) |
总的模型函数如下
1 | def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.5, print_cost=False): |
导入MNIST数据集后,采用OvM的思想训练10个分类器。进行分类就可以了。
每个分类器都是一个类别为正例,另外九个类别为反例。
这样$正例:反例=1:9$,虽然正例数目远远小于反例数目,并不会产生类别不平衡的问题,因为这个比例大致就是数据的真实分布产生的比例。
完整代码见此处