CS231n assignment1(KNN)
实验相关cs231n课程教程:Image Classification
这个实验是,用 KNN 算法,在CIFAR-10数据集上做图像分类。
KNN模型
train
对于KNN来说,训练只是初始化学习器的训练数据.1
2
3
4
5
6
7
8
9
10def train(self, X, y):
"""
Inputs:
- X: A numpy array of shape (num_train, D) containing the training data
consisting of num_train samples each of dimension D.
- y: A numpy array of shape (N,) containing the training labels, where
y[i] is the label for X[i].
"""
self.X_train = X
self.y_train = y
predict
根据测试数提供测试结果。
这里提供三种不同的计算距离的实现,分别使用0个,1个,2个循环。
第一步:计算每个测试样本到每个训练样本的距离1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def predict(self, X, k=1, num_loops=0):
"""
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k)
第二步:根据距离,选出最近的k个样本进行投票1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def predict_labels(self, dists, k=1):
"""
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
closest_y = self.y_train[np.argsort(dists[i])[:k]].flatten()
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_pred
积累几个numpy函数:
np.argsort(a) 返回a中排序后的index;sort(a)返回a中排序后的value
np.argmax(a) 返回a中最大值的index
np.bincount(a) 返回c(注意:a中的元素必须是整数)
for i in range(len(a)): c[i] = 0 for i in a: c[i]++

compute_distances
two_loop
1 | def compute_distances_two_loops(self, X): |
one_loop
1 | def compute_distances_one_loop(self, X): |
no_loop
1 | def compute_distances_no_loops(self, X): |
交叉验证法
原理参考西瓜书吧。西瓜书笔记2
实验目的是,用交叉验证来评估;对knn的k进行调参。
设置折数;k的调参范围;数据集划分;
1
2
3
4
5
6num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
# 把数据集均分为num_flods个小batch;
X_train_folds = np.array_split(X_train, num_folds)
Y_train_folds = np.array_split(y_train, num_folds)暴力寻找集合中的最优k
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20k_to_accuracies = {}
for k in k_choices:
k_to_accuracies[k]=[]
for i in range(num_folds):
X_te = X_train_folds[i]
y_te = Y_train_folds[i]
X_tr = np.vstack(X_train_folds[:i] + X_train_folds[i+1:])
y_tr = np.hstack(Y_train_folds[:i] + Y_train_folds[i+1:])
classifier.train(X_tr, y_tr)
for k_now in k_choices:
y_test_pred = classifier.predict(X_te, k=k_now)
num_correct = np.sum(y_test_pred == y_te)
accuracy = float(num_correct) / y_te.shape[0]
k_to_accuracies[k_now].append(accuracy)
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
最后的结果,图像表示就是
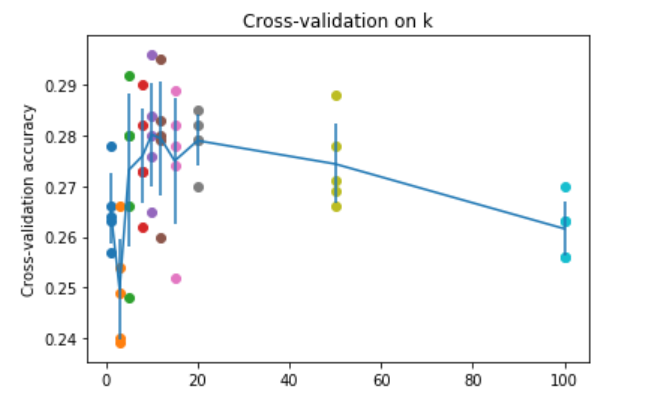
积累几个numpy的函数:
np.array_split(a,num) 把a均分为num个数组
np.vstack(tup) tup是一个元组,里面每个元素都是一个
np.array。vstack就是将元组里的数组纵向合并
np.hstack(a) 不同于
vstack,hstack是横向合并


