如何训练一个网络
数据预处理
关于数据预处理我们有3个常用的符号,数据矩阵$X$,假设其尺寸是$[N\times{D}]$($N$是数据样本的数量,D是数据的维度)。
均值减法(Mean subtraction)
均值减法是预处理最常用的形式。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。
在numpy中,该操作可以通过以下代码实现。1
X -= np.mean(X, axis=0)
而对于图像,更常用的是对所有像素都减去一个值,可以用以下代码实现,也可以在3个颜色通道上分别操作。1
X -= np.mean(X)
归一化(Normalization)
归一化是指将数据的所有维度都归一化,使其数值范围都近似相等。有两种常用方法可以实现归一化。
第一种是先对数据做零中心化(zero-centered)处理,然后每个维度都除以其标准差,实现代码为1
X /= np.std(X, axis=0)
第二种方法是对每个维度都做归一化,使得每个维度的最大和最小值是1和-1。这个预处理操作只有在确信不同的输入特征有不同的数值范围(或计量单位)时才有意义,但要注意预处理操作的重要性几乎等同于学习算法本身。在图像处理中,由于像素的数值范围几乎是一致的(都在0-255之间),所以进行这个额外的预处理步骤并不是很必要。
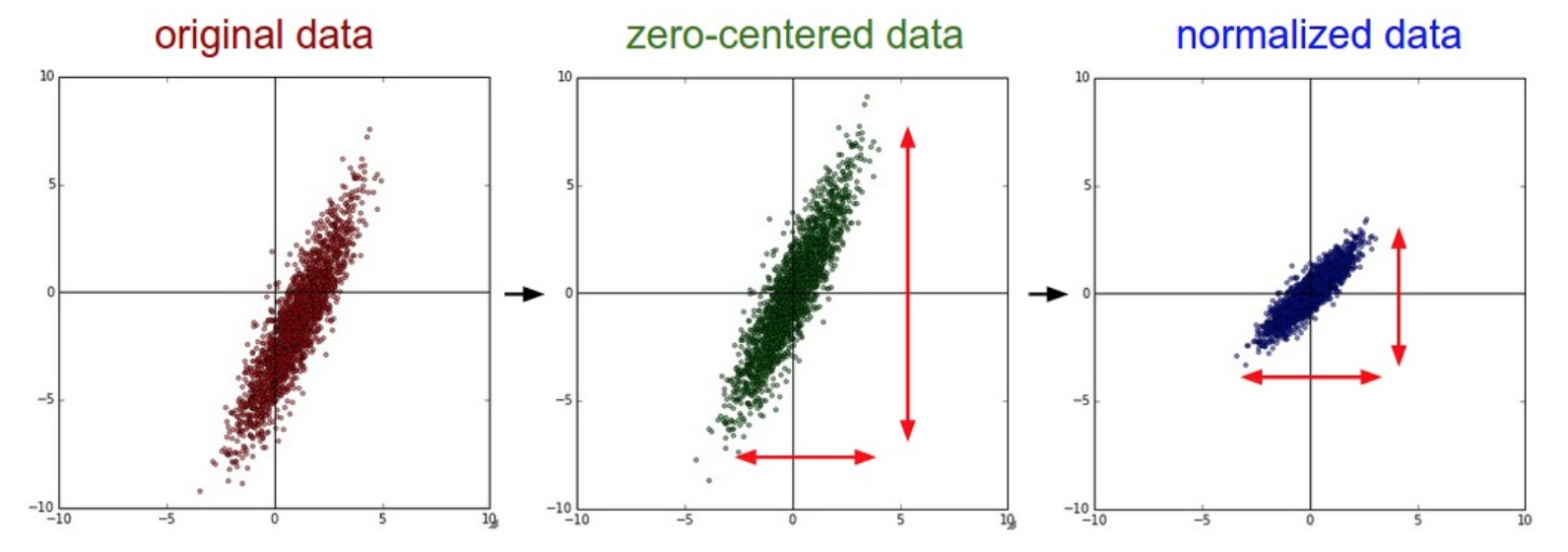
一般数据预处理流程:左边:原始的2维输入数据。中间:在每个维度上都减去平均值后得到零中心化数据,现在数据是以原点为中心的。右边:每个维度都除以其标准差来调整其数值范围。
PCA和白化(Whitening)
PCA中,先对数据进行零中心化处理,然后计算协方差矩阵,它展示了数据中的相关性结构。1
2
3# 假设输入数据矩阵X的尺寸为[N x D]
X -= np.mean(X, axis = 0) # 对数据进行零中心化(重要)
cov = np.dot(X.T, X) / X.shape[0] # 得到数据的协方差矩阵
数据协方差矩阵的第$(i,j)$个元素是数据第$i$个和第$j$个维度的协方差。具体来说,该矩阵的对角线上的元素是方差。还有,协方差矩阵是对称和半正定的,可以对数据协方差矩阵进行SVD(奇异值分解)运算。1
U,S,V = np.linalg.svd(cov)
U的列是特征向量,S是装有奇异值的1维数组(因为cov是对称且半正定的,所以S中元素是特征值的平方)。为了去除数据相关性,将已经零中心化处理过的原始数据投影到特征基准上:
1 | Xrot = np.dot(X,U) # 对数据去相关性 |
注意U的列是标准正交向量的集合(范式为1,列之间标准正交),所以可以把它们看做标准正交基向量。因此,投影对应x中的数据的一个旋转,旋转产生的结果就是新的特征向量。如果计算Xrot的协方差矩阵,将会看到它是对角对称的。np.linalg.svd的一个良好性质是在它的返回值U中,特征向量是按照特征值的大小排列的。我们可以利用这个性质来对数据降维,只要使用前面的小部分特征向量,丢弃掉那些包含的数据没有方差的维度。 这个操作也被称为主成分分析( Principal Component Analysis 简称PCA)降维:1
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced 变成 [N x 100]
经过上面的操作,将原始的数据集的大小由$[N\times{D}]$降到了$[N\times100]$,留下了数据中包含最大方差的100个维度。通常使用PCA降维过的数据训练线性分类器和神经网络会达到非常好的性能效果,同时还能节省时间和存储器空间。
白化(whitening)的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵。该操作的代码如下:
1 | # 对数据进行白化操作: |
注意:该变换的一个缺陷是在变换的过程中可能会夸大数据中的噪声,这是因为它将所有维度都拉伸到相同的数值范围,这些维度中也包含了那些只有极少差异性(方差小)而大多是噪声的维度。在实际操作中,这个问题可以用更强的epsilon值来解决(例如:采用比1e-5更大的值)。
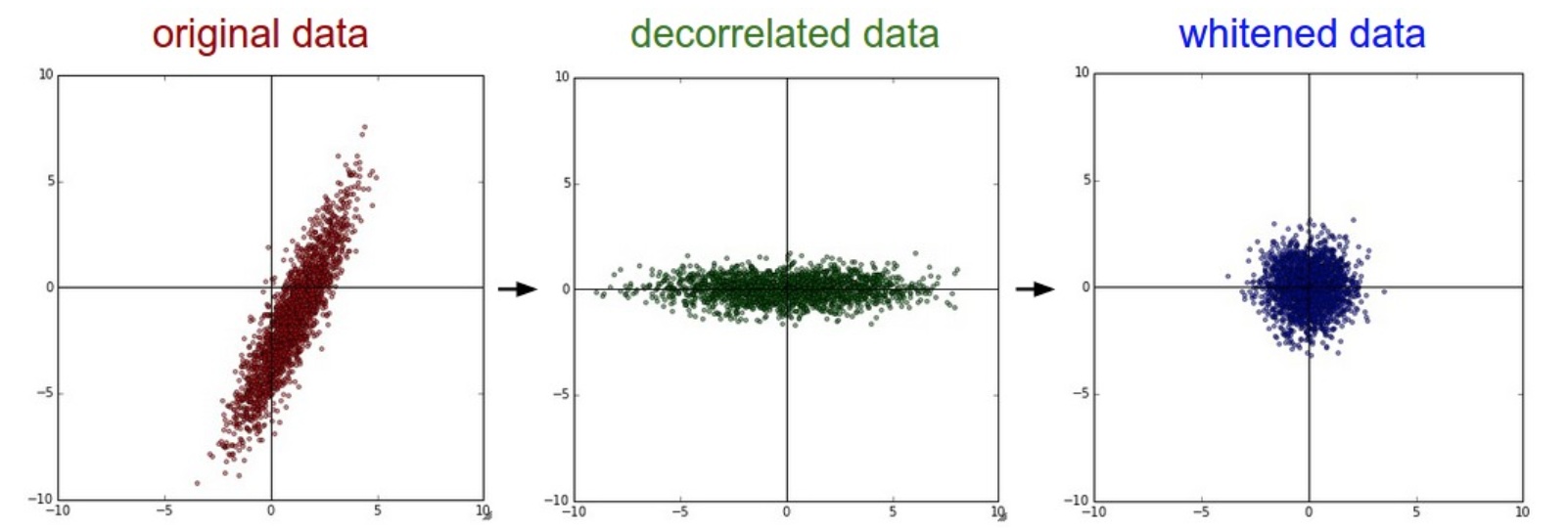
左边:二维的原始数据。中间:经过PCA操作的数据。可以看出数据首先是零中心的,然后变换到了数据协方差矩阵的基准轴上。这样就对数据进行了解相关(协方差矩阵变成对角阵)。右边:每个维度都被特征值调整数值范围,将数据协方差矩阵变为单位矩阵。从几何上看,就是对数据在各个方向上拉伸压缩,使之变成服从高斯分布的一个数据点分布。
我们可以使用CIFAR-10数据将这些变化可视化出来。CIFAR-10训练集的大小是50000x3072,其中每张图片都可以拉伸为3072维的行向量。我们可以计算$[3072\times3072]$的协方差矩阵然后进行奇异值分解(比较耗费计算性能),那么经过计算的特征向量看起来是什么样子呢?
- 首先是一个用于演示的集合,含49张图片:

- 第二张是3072个特征值向量中的前144个。靠前面的特征向量解释了数据中大部分的方差,可以看见它们与图像中较低的频率相关。

- 第三张是49张经过了PCA降维处理的图片,展示了144个特征向量。这就是说,展示原始图像是每个图像用3072维的向量,向量中的元素是图片上某个位置的像素在某个颜色通道中的亮度值。而现在每张图片只使用了一个144维的向量,其中每个元素表示了特征向量对于组成这张图片的贡献度。为了让图片能够正常显示,需要将144维度重新变成基于像素基准的3072个数值。因为U是一个旋转,可以通过乘以U.transpose()[:144,:]来实现,然后将得到的3072个数值可视化。可以看见图像变得有点模糊了,这正好说明前面的特征向量获取了较低的频率。然而,大多数信息还是保留了下来。

- 第四张是将“白化”后的数据进行显示。其中144个维度中的方差都被压缩到了相同的数值范围。然后144个白化后的数值通过乘以U.transpose()[:144,:]转换到图像像素基准上。现在较低的频率(代表了大多数方差)可以忽略不计了,较高的频率(代表相对少的方差)就被夸大了。

小结
实践操作:这里提到PCA和白化主要是为了介绍的完整性,实际上在卷积神经网络中并不会采用这些变换。然而对数据进行零中心化操作还是非常重要的,对每个像素进行归一化也很常见。
常见错误:进行预处理很重要的一点是:任何预处理策略(比如数据均值)都只能在训练集数据上进行计算,算法训练完毕后再应用到验证集或者测试集上。例如,如果先计算整个数据集图像的平均值然后每张图片都减去平均值,最后将整个数据集分成训练/验证/测试集,那么这个做法是错误的。应该怎么做呢?应该先分成训练/验证/测试集,只是从训练集中求图片平均值,然后各个集(训练/验证/测试集)中的图像再减去这个平均值。
选择网络结构
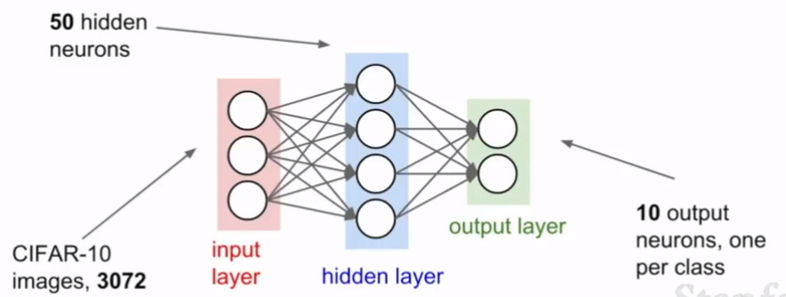
例如这个单隐层网络,一开始有50个隐层神经元,但基本上,我们可以选择任何我们想要的网络结构。
初始化网络
错误:全零初始化
在训练完毕后,虽然不知道网络中每个权重的最终值应该是多少,但如果数据经过了恰当的归一化的话,就可以假设所有权重数值中大约一半为正数,一半为负数。这样,一个听起来蛮合理的想法就是把这些权重的初始值都设为0吧,因为在期望上来说0是最合理的猜测。这个做法错误的!因为如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新。换句话说,如果权重被初始化为同样的值,神经元之间就失去了不对称性的源头。
小随机数初始化
因此,权重初始值要非常接近0又不能等于0。解决方法就是将权重初始化为很小的数值,以此来打破对称性。其思路是:如果神经元刚开始的时候是随机且不相等的,那么它们将计算出不同的更新,并将自身变成整个网络的不同部分。小随机数权重初始化的实现方法是:1
W = 0.01 * np.random.randn(D,H)
其中randn函数是基于零均值和标准差的一个高斯分布来生成随机数的。根据这个式子,每个神经元的权重向量都被初始化为一个随机向量,而这些随机向量又服从一个多变量高斯分布,这样在输入空间中,所有的神经元的指向是随机的。也可以使用均匀分布生成的随机数,但是从实践结果来看,对于算法的结果影响极小。
warn:并不是小数值一定会得到好的结果。例如,一个神经网络的层中的权重值很小,那么在反向传播的时候就会计算出非常小的梯度(因为梯度与权重值是成比例的)。这就会很大程度上减小反向传播中的“梯度信号”,在深度网络中,就会出现问题。
使用1/sqrt(n)校准方差
上面做法存在一个问题,随着输入数据量的增长,随机初始化的神经元的输出数据的分布中的方差也在增大。我们可以除以输入数据量的平方根来调整其数值范围,这样神经元输出的方差就归一化到1了。也就是说,建议将神经元的权重向量初始化为:1
w = np.random.randn(n) / sqrt(n)
其中n是输入数据的数量。这样就保证了网络中所有神经元起始时有近似同样的输出分布。实践经验证明,这样做可以提高收敛的速度。
稀疏初始化(Sparse initialization)
另一个处理非标定方差的方法是将所有权重矩阵设为0,但是为了打破对称性,每个神经元都同下一层固定数目的神经元随机连接(其权重数值由一个小的高斯分布生成)。一个比较典型的连接数目是10个。
偏置(biases)的初始化
通常将偏置初始化为0,这是因为随机小数值权重矩阵已经打破了对称性。对于ReLU非线性激活函数,有研究人员喜欢使用如0.01这样的小数值常量作为所有偏置的初始值,这是因为他们认为这样做能让所有的ReLU单元一开始就激活,这样就能保存并传播一些梯度。然而,这样做是不是总是能提高算法性能并不清楚(有时候实验结果反而显示性能更差),所以通常还是使用0来初始化偏置参数。
实践中,当前的推荐是使用ReLU激活函数,并且使用w = np.random.randn(n) * sqrt(2.0/n)来进行权重初始化,关于这一点,这篇文章有讨论。
学习之前:合理性检查(sanity checks)
在进行费时费力的最优化之前,最好进行一些合理性检查:
寻找特定情况的正确损失值
在使用小参数进行初始化时,确保得到的损失值与期望一致。
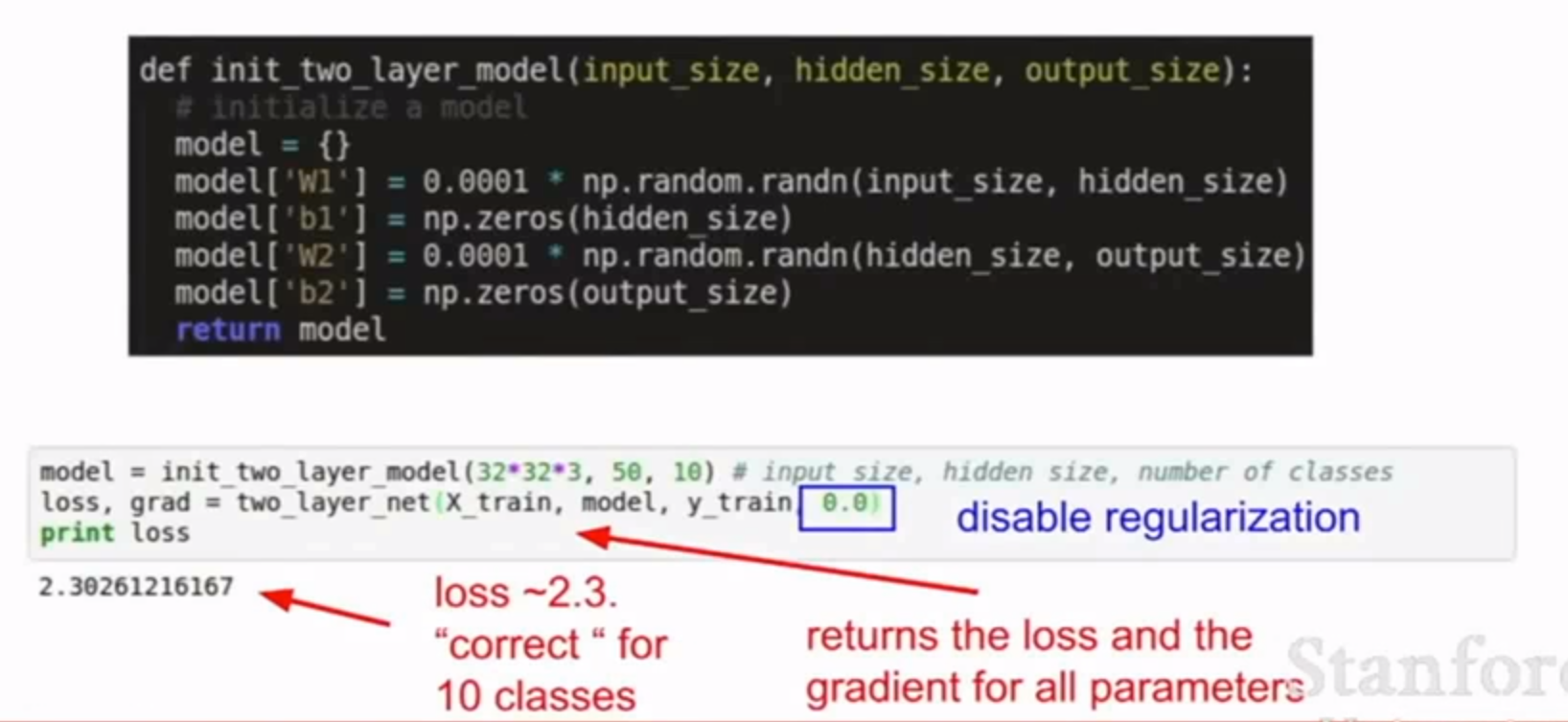
当我们weight很小且很分散的时候,趋近于随机分类。所以Softmax损失(让正则化强度为0),约等于$-\log{\frac{1}{C}}$。
例如,对于一个跑CIFAR-10的Softmax分类器,一般期望它的初始损失值是2.302,这是因为初始时预计每个类别的概率是0.1(因为有10个类别),然后Softmax损失值正确分类的负对数概率:-ln(0.1)=2.302。
提高正则化强度时导致损失值变大
提高正则化强度,看损失值是否变大

对小数据子集过拟合
最后也是最重要的一步,在整个数据集进行训练之前,尝试在一个很小的数据集上进行训练(比如20个数据),然后确保能到达0的损失值。
进行这个实验的时候,最好让正则化强度为0,不然它会阻止得到0的损失。
但是注意,能对小数据集进行过拟合并不代表万事大吉,依然有可能存在不正确的实现。比如,因为某些错误,数据点的特征是随机的,这样算法也可能对小数据进行过拟合,但是在整个数据集上跑算法的时候,就没有任何泛化能力。
现在就全部完成了 完整性检查操作(sanity checks)
超参数调参
首先调学习率
全部数据集,小的正则化项,首先进行学习率的调参。
可以试一些学习率的值。这里用了1e-6可以看到损失值几乎不变,原因可能是学习率太小。
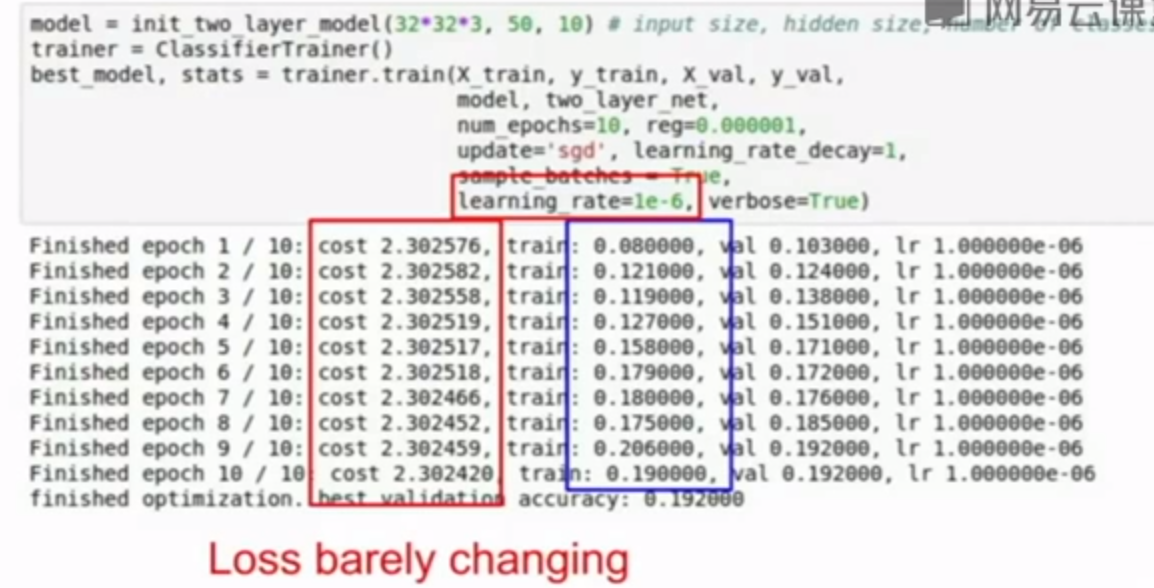
但是,注意到虽然cost几乎不变,但准确度却提高到了20%左右,是为什么呢?
原因:学习率太小了,梯度下降步幅非常小,因此我们的损失项很接近。但是所有的分布都在朝着正确的方向轻微的移动,weight也在朝着正确的方向改变。正确率有较大提升是因为,我们认为分数最大的为该样本的分类,虽然分布还是很分散,但是已经向正确方向有所偏移,大小关系应该有所改变。
然后选择了另一个极端,1e6一个非常大的学习率
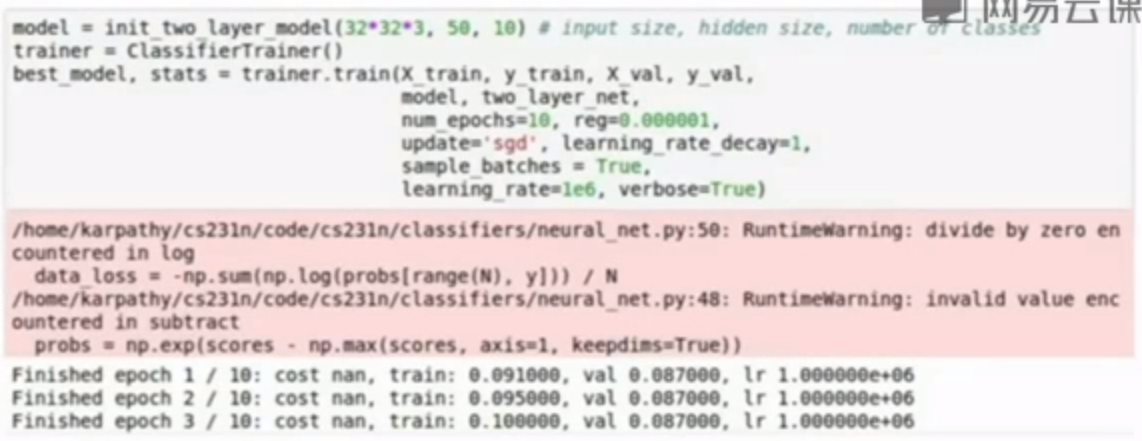
损失值爆炸变成NaN,原因可能是学习率太大,可以试试更小的学习率
一般我们的学习率设为[1e-3,1e-5],这是一个我们想要交叉验证的粗略范围。可以在这个范围里试一试不同的学习率。
超参数优化
调参的目标: 找到交叉验证中表现最好的参数(组合),即在训练集上训练,验证集上测试,选验证集高的参数。
大概分为两步。
第一步,粗略选择好的参数来确定一个区间
首先选几个比较分散的数值,然后用几个epochs来训练。通过几个epochs就可以知道那些是比较好的参数,那些是比较差的。通常只要这样做就可以发现一个较好的区间。例如首先用5个epochs进行搜索
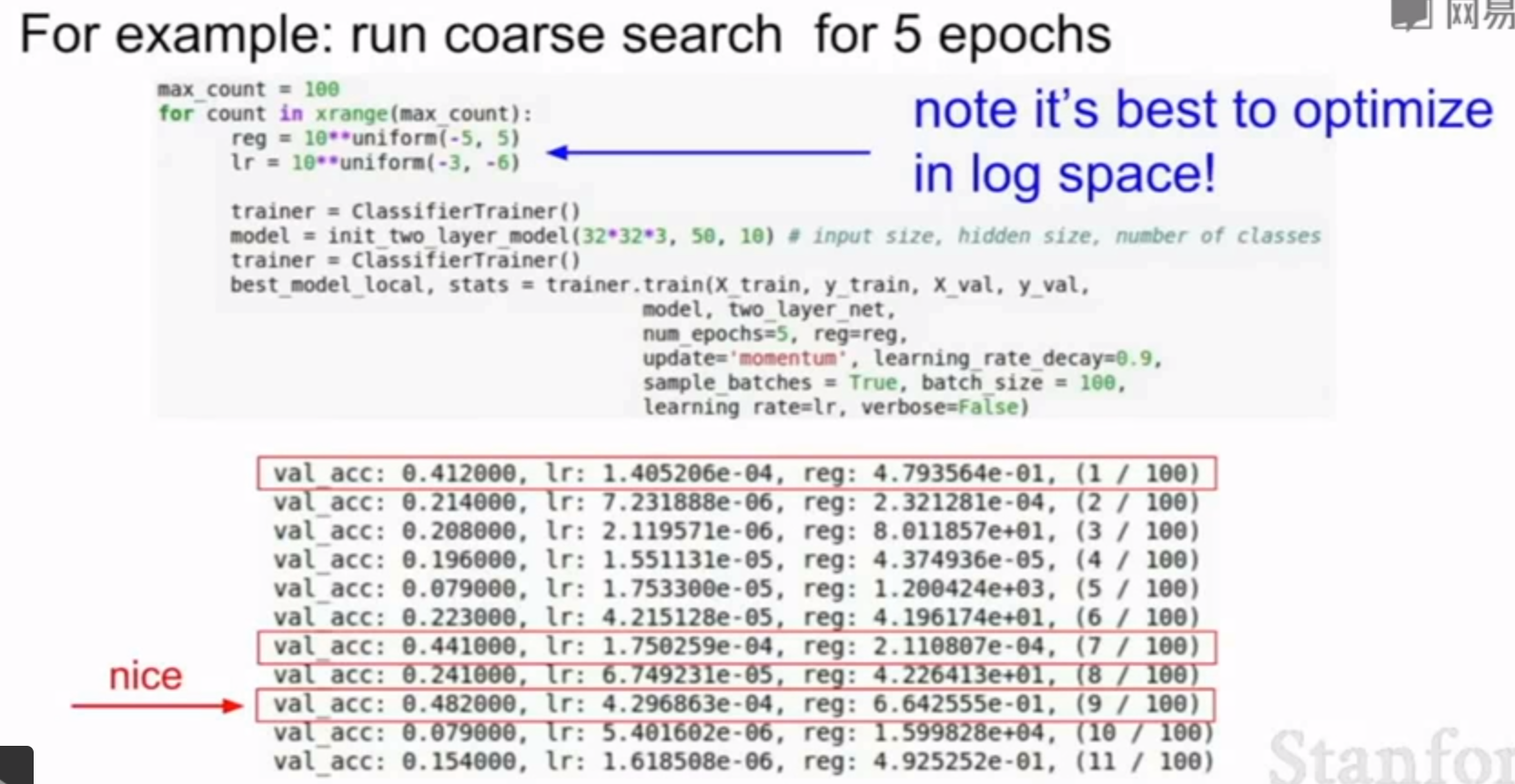
这些区间就是我们想要进一步细化的区域。
第二步,是在区间内进行精确地搜索
接下来就可以调整变化范围,在第一步找到的区间中,精确的搜索
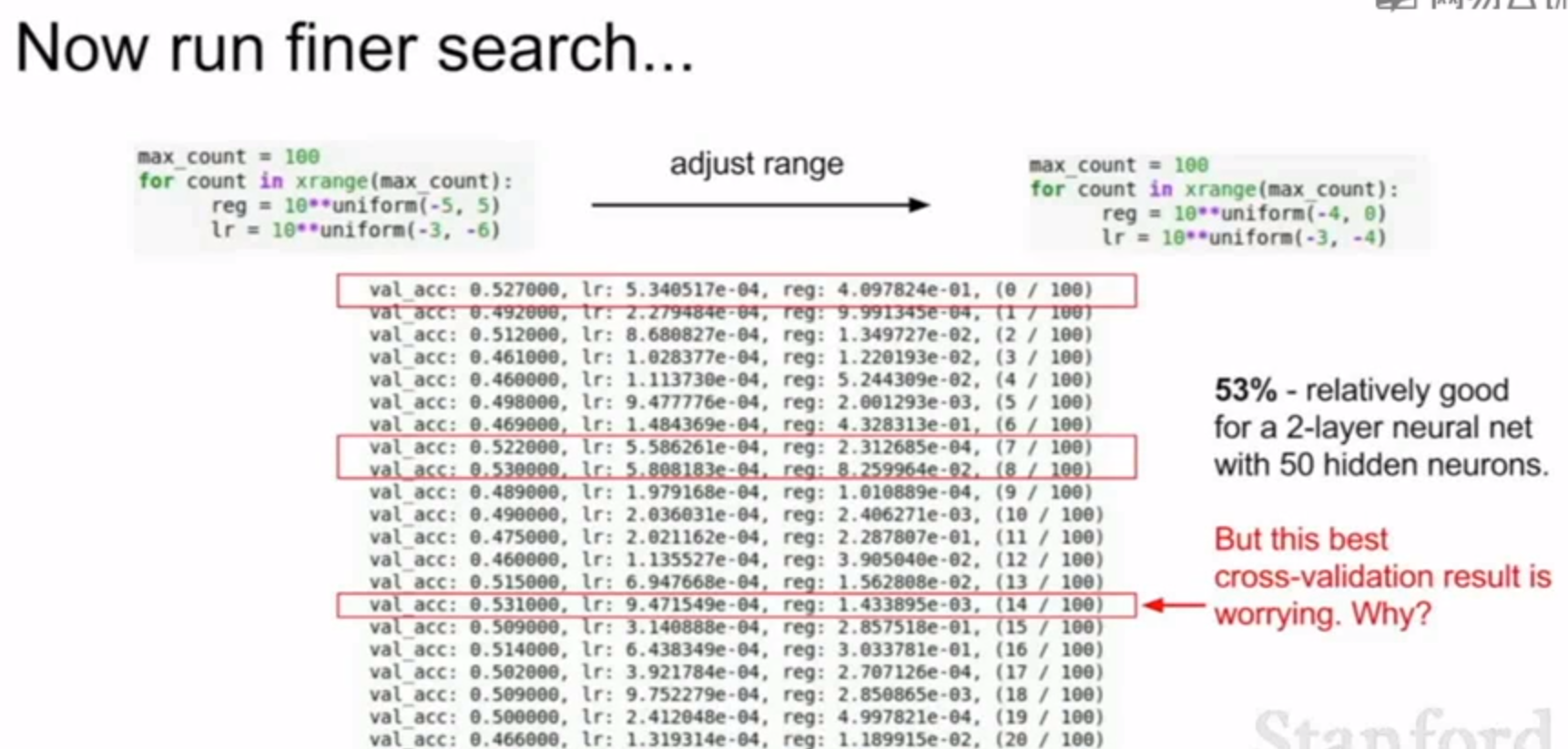
需要注意的一点是,通常采用对数来优化,效果会更好。
比如用在[0.01,100]与其用均匀采样,不如用10的幂次进行采样。
因为学习率是乘以梯度进行更新,具有乘法效应,所以考虑学习率的时候用一些值得乘或除的值更合理。
这就产生了一个问题,这里所有好的学习率都在1e-4左右,如果我们一开始的调参区间就是[0,1e-4]的话,这样最后选出的学习率都在这个区间的边缘。这样不太好,因为我们没法在全部的空间上充分寻找,可能1e-5或者1e-6中也有我们想要最好的结果。
参数搜索时的采样
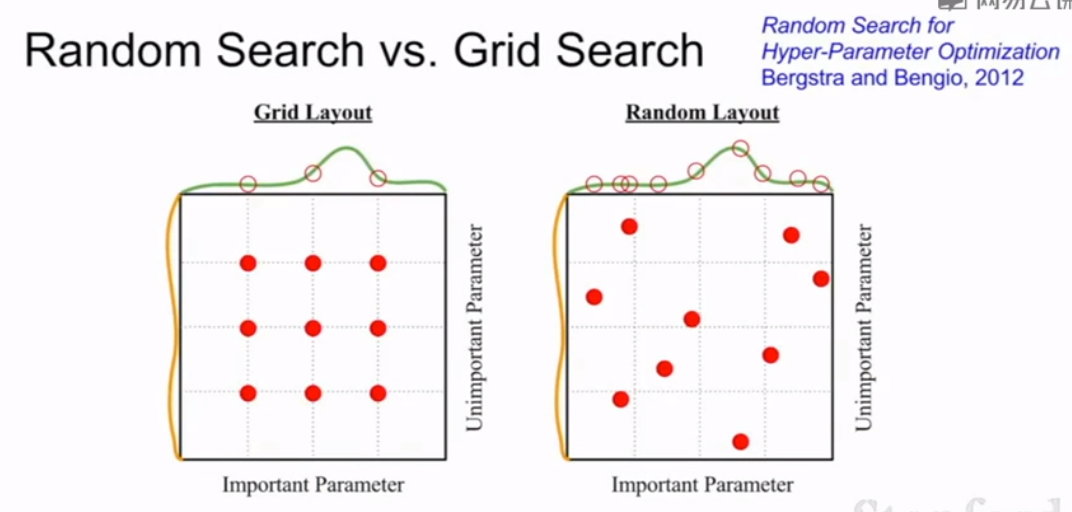
网格采样不如用一种随机排列的方式进行采样。
随机采样是考虑对一个超过一个变量的函数而言,算是一种稍微有效的降维,可以获得更多有用的信息。
检查整个学习过程
在训练神经网络的时候,应该跟踪多个重要数值。这些数值输出的图表是观察训练进程的一扇窗口,是直观理解不同的超参数设置效果的工具,从而知道如何修改超参数以获得更高效的学习过程。
在下面的图表中,x轴通常都是表示周期(epochs)单位,该单位衡量了在训练中每个样本数据都被观察过次数的期望(一个周期意味着每个样本数据都被观察过了一次)。相较于迭代次数(iterations),一般更倾向跟踪周期,这是因为迭代次数与数据的批尺寸(batchsize)有关,而批尺寸的设置又可以是任意的。
损失函数
训练期间第一个要跟踪的数值就是损失值,它在前向传播时对每个独立的批数据进行计算。下图展示的是随着损失值随时间的变化,尤其是曲线形状会给出关于学习率设置的情况:
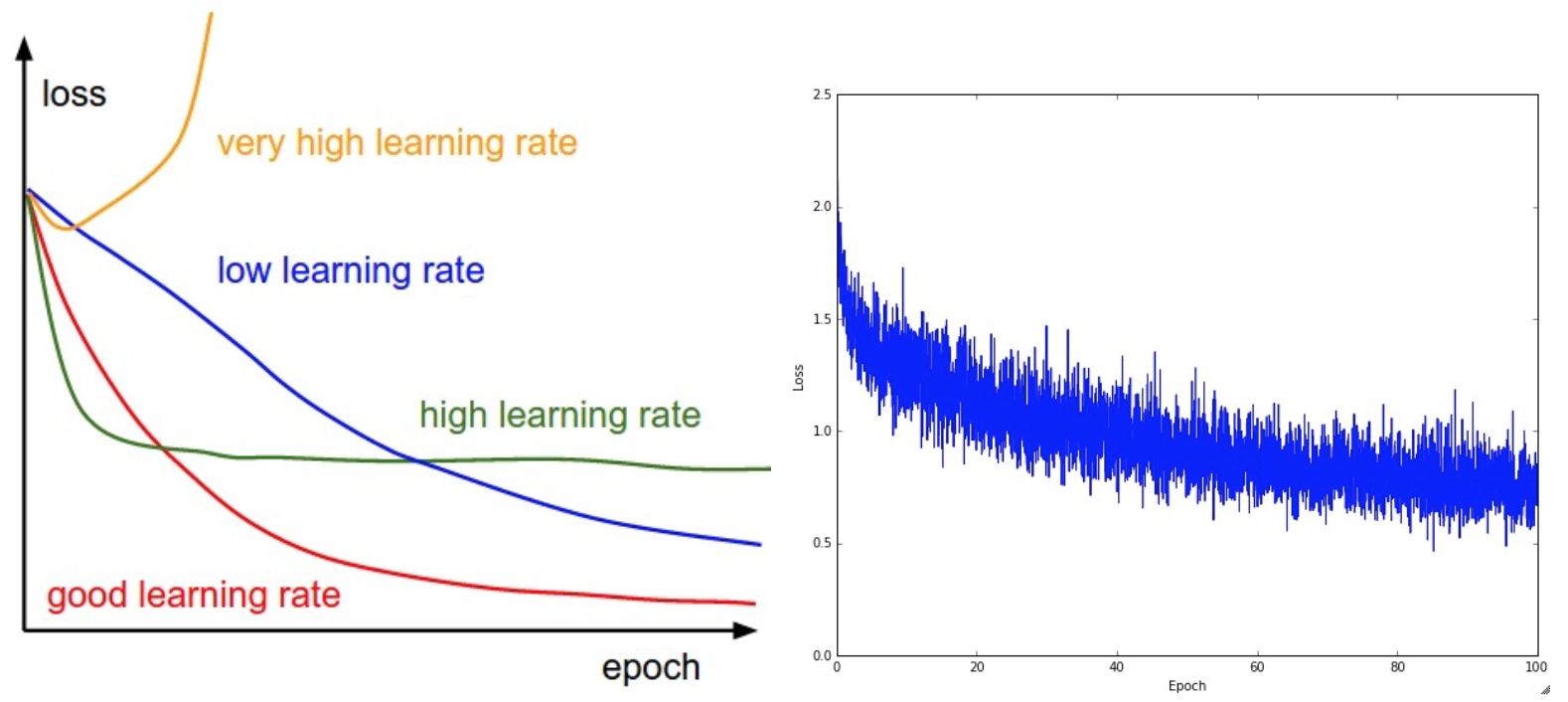
左图展示了不同的学习率的效果。过低的学习率导致算法的改善是线性的。高一些的学习率会看起来呈几何指数下降,更高的学习率会让损失值很快下降,但是接着就停在一个不好的损失值上(绿线)。这是因为最优化的“能量”太大,参数在混沌中随机震荡,不能最优化到一个很好的点上。
右图显示了一个典型的随时间变化的损失函数值,在CIFAR-10数据集上面训练了一个小的网络,这个损失函数值曲线看起来比较合理(虽然可能学习率有点小,但是很难说),而且指出了批数据的数量可能有点太小(因为损失值的噪音很大)。
损失值的震荡程度和批尺寸(batch size)有关,当批尺寸为1,震荡会相对较大。当批尺寸就是整个数据集时震荡就会最小,因为每个梯度更新都是单调地优化损失函数(除非学习率设置得过高)。
有的研究者喜欢用对数域对损失函数值作图。因为学习过程一般都是采用指数型的形状,图表就会看起来更像是能够直观理解的直线,而不是呈曲棍球一样的曲线状。还有,如果多个交叉验证模型在一个图上同时输出图像,它们之间的差异就会比较明显。
有时候损失函数看起来很有意思:lossfunctions.tumblr.com。
当在你观察学习率曲线的时候,如果它在一定时间内很平滑,然后突然开始下降,可能是初始值没有设好。
从图上可以看出,刚开始的时候梯度变化并不太好,什么也没学到;到达某点后突然开始下降,就像刚开始训练一样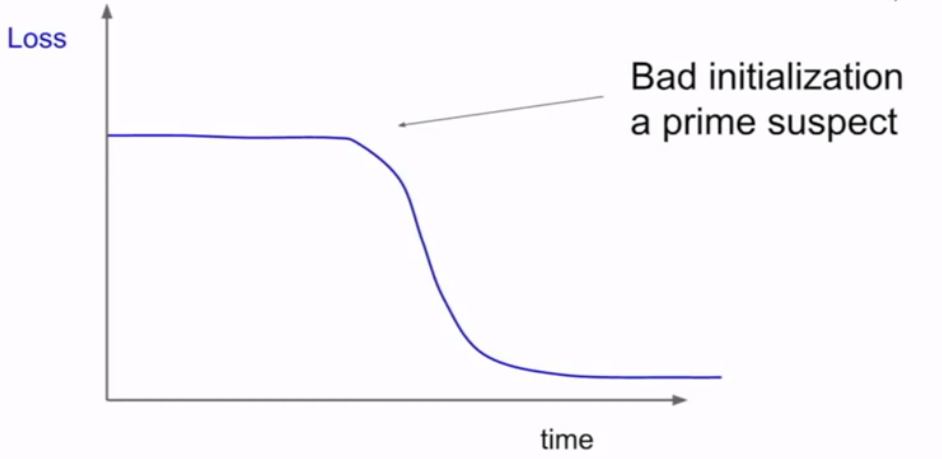
训练集和验证集准确率
在训练分类器的时候,需要跟踪的第二重要的数值是验证集和训练集的准确率。这个图表能够展现知道模型过拟合的程度:
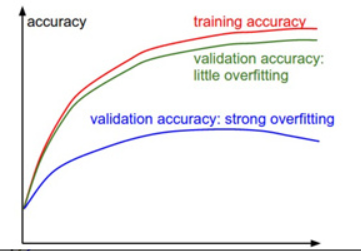
在训练集准确率和验证集准确率中间的空隙指明了模型过拟合的程度。在图中,蓝色的验证集曲线显示相较于训练集,验证集的准确率低了很多,这就说明模型有很强的过拟合。遇到这种情况,就应该增大正则化强度(更强的L2权重惩罚,更多的随机失活等)或收集更多的数据。另一种可能就是验证集曲线和训练集曲线如影随形,这种情况说明你的模型容量还不够大:应该通过增加参数数量让模型容量更大些。
————————————————————————————————————————
权重更新比例
最后一个应该跟踪的量是权重中更新值的数量和全部值的数量之间的比例。注意:是更新的,而不是原始梯度(比如,在普通sgd中就是梯度乘以学习率)。需要对每个参数集的更新比例进行单独的计算和跟踪。一个经验性的结论是这个比例应该在1e-3左右。如果更低,说明学习率可能太小,如果更高,说明学习率可能太高。下面是具体例子:
1 | # 假设参数向量为W,其梯度向量为dW |
相较于跟踪最大和最小值,有研究者更喜欢计算和跟踪梯度的范式及其更新。这些矩阵通常是相关的,也能得到近似的结果。
每层的激活数据及梯度分布
一个不正确的初始化可能让学习过程变慢,甚至彻底停止。还好,这个问题可以比较简单地诊断出来。其中一个方法是输出网络中所有层的激活数据和梯度分布的柱状图。直观地说,就是如果看到任何奇怪的分布情况,那都不是好兆头。比如,对于使用tanh的神经元,我们应该看到激活数据的值在整个[-1,1]区间中都有分布。如果看到神经元的输出全部是0,或者全都饱和了往-1和1上跑,那肯定就是有问题了。
第一层可视化
最后,如果数据是图像像素数据,那么把第一层特征可视化会有帮助:

将神经网络第一层的权重可视化的例子。左图中的特征充满了噪音,这暗示了网络可能出现了问题:网络没有收敛,学习率设置不恰当,正则化惩罚的权重过低。右图的特征不错,平滑,干净而且种类繁多,说明训练过程进行良好。