Keras Samples: LeNet-5 on cifar10 dataset
从keras导入cifar10数据库
1 | def load_cifar10(num_training=49000, num_validation=1000, num_test=1000): |
labels需要进行one-hot因为预测采用softmax函数,需要每个标签的shape为(num_classes,)。
LeNet-5模型
LeNet-5,一个7层的卷积神经网络,被很多银行用于识别支票上的手写数字。

1 | def simple_model(input_shape, num_classes=10): |
通过训练集和验证集的差距可以看出,模型对训练集过拟合了。
训练曲线如下:
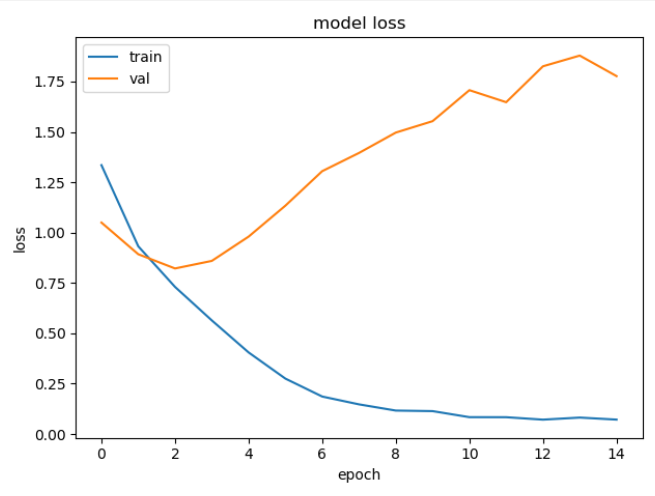
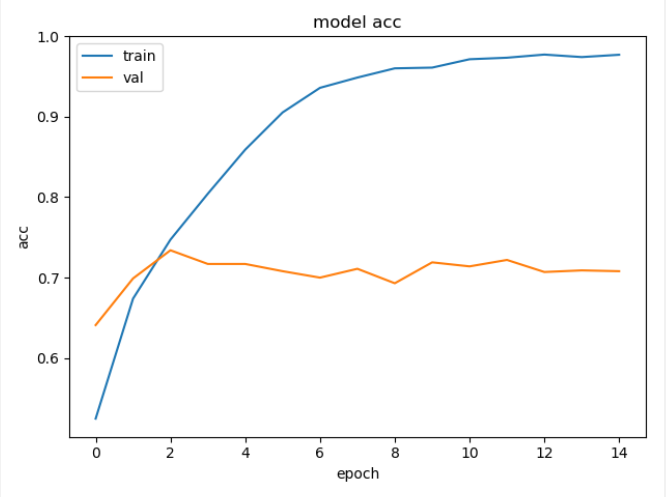
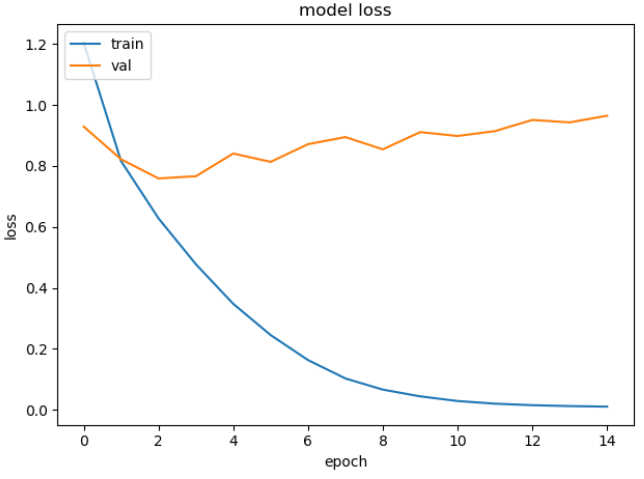
可以看到训练中,虽然train的loss曲线逐渐下降,但是val的loss曲线却有上升。初以为有可能是学习率的问题。但是将学习率将为1e-3后,15个epoch后的结果如下:
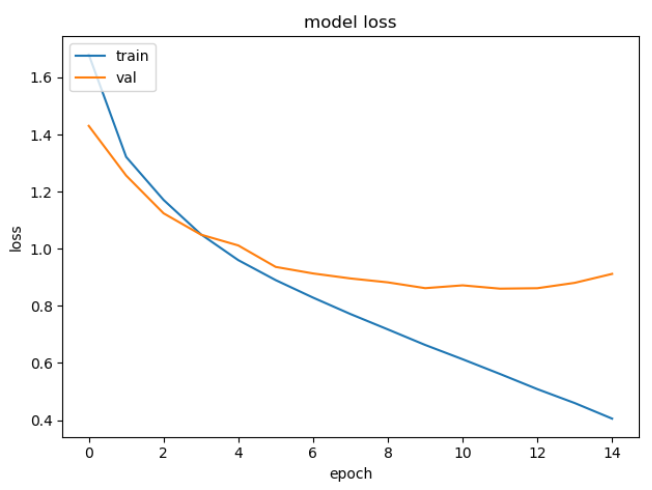
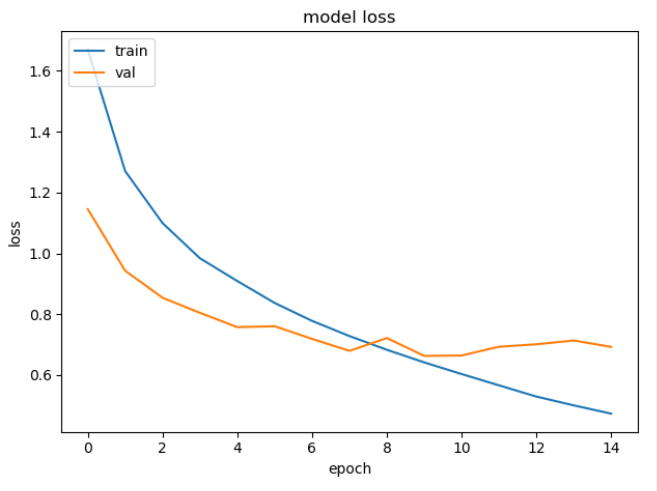
貌似不错?其实train的loss曲线还比较直,还没有训练好,再把训练时间拉长,45个epoch后的结果如下:
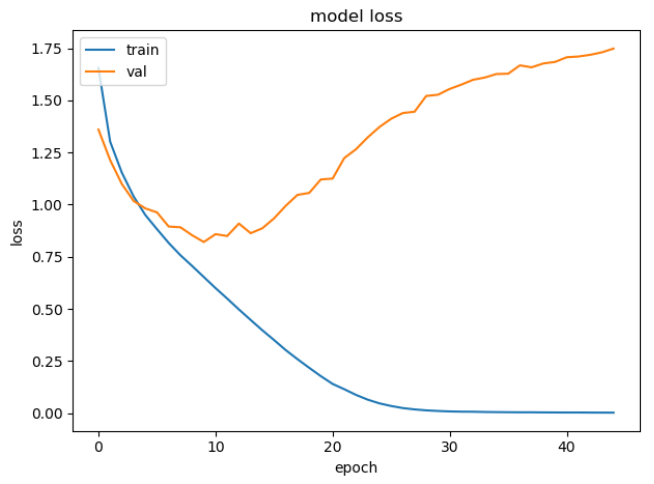
所以,val的loss曲线上升,并不是学习率的问题,而是模型过拟合产生的!
LeNet-5 + Batch Normalization
为减少模型的过拟合,希望加入各种正则化手段。
1 | def simple_model(input_shape, num_classes=10): |
加上BN之后有点点好转,尝试把batchsize变小一点,以增加的随机性强度,无明显效果。

LeNet-5 + BN + Dropout
只有两个全连接层,所以,只能在之间防止一个Dropout层。试着把rate调的高一点(rate是失活神经元比例)。
1 | def simple_model(input_shape, num_classes=10): |

结果还是差强人意,后觉得是网络结构太复杂了?尝试减少层数,train结果反而也将下来了。
把epoch增加到50:
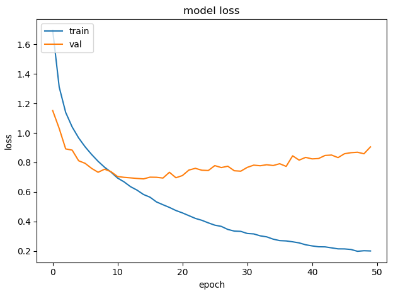
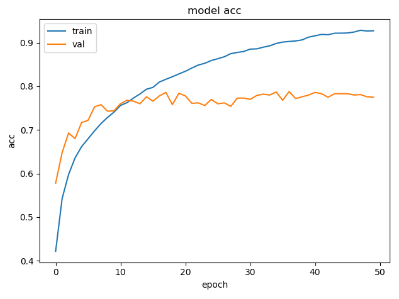
模型还是很容易拟合训练集,10个epoch之后,训练对val的损失或准确度的贡献就不大了。1
2
3
4
5
6"""
Train Loss = 0.029131395354
Train Accuracy = 0.997387755102
Val Loss = 0.905600978374
Val Accuracy = 0.775
"""
完整代码
1 |
|