cs231n assignment3(RNN_Captioning)
这次的作业内容是从 Image Caption 这个问题入手,即给定一张图片,生成对图片的文字描述。
大概的做法是这样的,用一个预训练的 CNN 把图片提取特征,然后那这个特征初始化 RNN(LSTM) 的 hidden state,用 RNN(LSTM) 生成一句话。
这里的 CNN 主要就是一个encoder,负责把图片压缩成一个语义向量,而 RNN(LSTM) 则是一个decoder,也是一个语言模型(language model),负责从这个语义向量解码出自然语言。
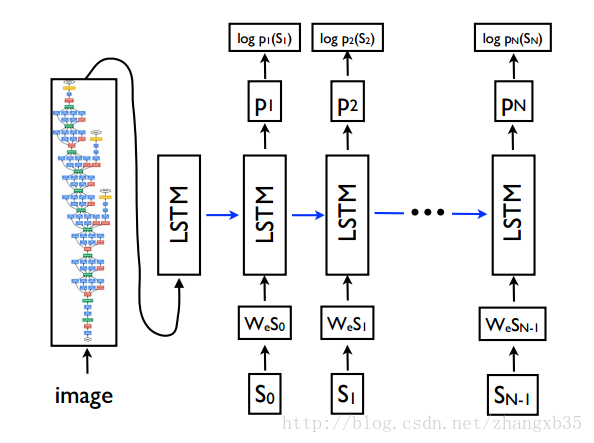
COCO dataset
本次实验用的数据是微软2014年发布的COCO dataset,这也是用来测试image caption的标准数据集。
COCO数据集包含80,000个训练集图像40,000验证集图像, each annotated with 5 captions written by workers on Amazon Mechanical Turk.
下面看其中一张样本。

Vanilla RNN Step
Forward Pass
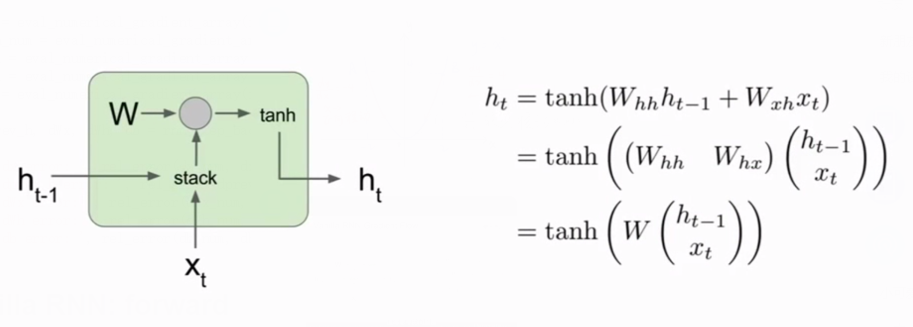
RNN 的 step_forward 公式很简单,
1 | def rnn_step_forward(x, prev_h, Wx, Wh, b): |
Backward Pass
反向传播和之前的全连接层也差不多,也挺简单。注意$\tanh(x)$的导数
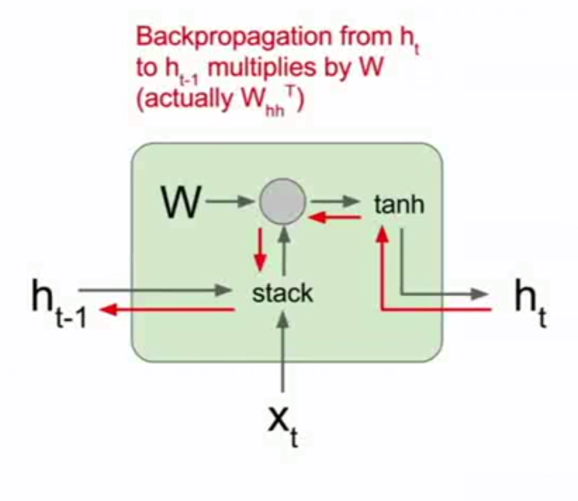
1 | def rnn_step_backward(dnext_h, cache): |
Vanilla RNN
如图,RNN的部分就是将前面的RNN step用for loop简单组装一下
Forward Pass
把前面写的forward step组合一下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def rnn_forward(x, h0, Wx, Wh, b):
"""
Run a vanilla RNN forward on an entire sequence of data. We assume an input
sequence composed of T vectors, each of dimension D. The RNN uses a hidden
size of H, and we work over a minibatch containing N sequences. After running
the RNN forward, we return the hidden states for all timesteps.
Inputs:
- x: Input data for the entire timeseries, of shape (N, T, D).
- h0: Initial hidden state, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,)
Returns a tuple of:
- h: Hidden states for the entire timeseries, of shape (N, T, H).
- cache: Values needed in the backward pass
"""
N, T, D = x.shape
_, H = h0.shape
cache = []
h = np.zeros((N, T, H))
for t in range(T):
h0, cache_tmp = rnn_step_forward(x[:, t, :], h0, Wx, Wh, b)
h[:, t, :] = h0
cache.append(cache_tmp)
return h, cache
Backward Pass
1 | def rnn_backward(dh, cache): |
Word Embedding
另外还要实现 word embedding 层,现在我们的就是给定词表(词表有V个词)中的下标(下标的范围是0 <= idx < V),映射到 D 维向量。
我们的RNN在时间序列的长度是T,也就是说要循环T次。所以,我们输入的一条样本$x_i$应该是shape =(T,)可以理解成一个有T个字符。但我们每次输入的是一个batch(batch size用N表示),即每次输入的样本shape =(N,T)。
这N*T每个都是一个字符(字符的种类应该不超过V种),word embedding就是把这些字符用相应的编码来替换(如本来是”a”,用一个长度为D的编码假如是”00001”来替换),经过word embdding后的x就是shape = (N,T,D)。
Forward Pass
把X中的每个元素(每个元素都属于0 <= idx < V的范围),用w中的编码表示。
实现可以先用for loop的写法,加深理解。1
2
3
4
5
6
7N, T = x.shape
V, D = W.shape
out = np.zeros((N, T, D))
for n in range(N):
for t in range(T):
tmp = W[x[n,t]]
out[n, t, :] = tmp
简洁写法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def word_embedding_forward(x, W):
"""
Forward pass for word embeddings. We operate on minibatches of size N where
each sequence has length T. We assume a vocabulary of V words, assigning each
word to a vector of dimension D.
Inputs:
- x: Integer array of shape (N, T) giving indices of words. Each element idx
of x muxt be in the range 0 <= idx < V.
- W: Weight matrix of shape (V, D) giving word vectors for all words.
Returns a tuple of:
- out: Array of shape (N, T, D) giving word vectors for all input words.
- cache: Values needed for the backward pass
"""
out = W[x]
cache = x, W
return out, cache
Backward Pass
backword要用到np.add.at()函数,参考:numpy.ufunc.at
同样可以先写出for loop的版本1
2
3
4
5x, W = cache
dW = np.zeros(W.shape)
for n in range(N):
for t in range(T):
dW[x[n, t]] += dout[n, t, :]
简洁写法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def word_embedding_backward(dout, cache):
"""
Backward pass for word embeddings. We cannot back-propagate into the words
since they are integers, so we only return gradient for the word embedding
matrix.
HINT: Look up the function np.add.at
Inputs:
- dout: Upstream gradients of shape (N, T, D)
- cache: Values from the forward pass
Returns:
- dW: Gradient of word embedding matrix, of shape (V, D).
"""
N, T, D = dout.shape
x, W = cache
dW = np.zeros(W.shape)
np.add.at(dW, x, dout)
return dW
Loss and grads
loss和grads就按照他给的层结构进行组装,然后再backward就ok了1
2
3
4
5
6
7
8
9
10h0, cache1 = affine_forward(features, W_proj, b_proj) # h0 (N, H)
x, cache2 = word_embedding_forward(captions_in, W_embed) # x (N, T, D)
h, cache3 = rnn_forward(x, h0, Wx, Wh, b)
scores, cache4 = temporal_affine_forward(h, W_vocab, b_vocab)
loss, dscores = temporal_softmax_loss(scores, captions_out, mask)
dh, grads['W_vocab'], grads['b_vocab'] = temporal_affine_backward(dscores, cache4)
dx, dh0, grads['Wx'], grads['Wh'], grads['b'] = rnn_backward(dh, cache3)
grads['W_embed'] = word_embedding_backward(dx, cache2)
_, grads['W_proj'], grads['b_proj'] = affine_backward(dh0, cache1)
Sample
Sample是再测试的时候,根据输入的图片特征,自己生成captions。
具体过程如下:
1.输入:
features 是经过CNN训练后得出来一个batch图片的特征,维度时$[N\times D]$max_length 是RNN训练的轮数(时间序列的长度)
2.预处理:获取$h_0$,$x_1$
第一步,对特征维度进行处理,变成$h_0$(N,H),即RNN中h的初始值。之后将进行对图像特征的“解码”工作。
第二步,RNN的第一个$x_1$是<start>这个字符,这是$x_1$的原始形态(N,)的一个向量,每个向量包含<start>这个字符,但这不是$x_1$,需要一个embedding操作,进行编码得到$x_1$(N,D)。
3.循环max_length次rnn step:
这个就很简单了,如图根据$h_{t-1}$和$x_t$算出$h_t$;
再根据$h_t$算出预测的$y_t$;
对$y_t$进行embedding就是下次的输入$x_{t+1}$;
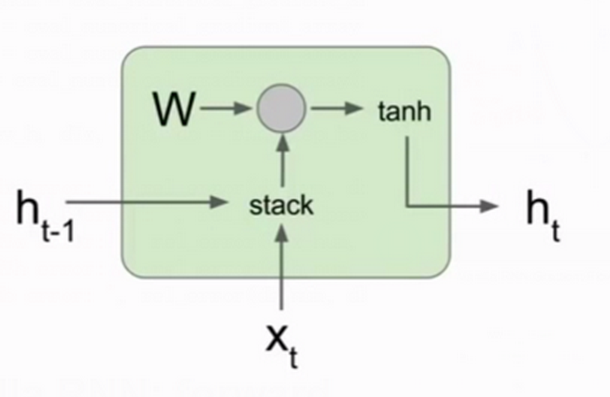
4.最后的caption就是我们所有层输入的字符(进行embedding之前的字符)。
代码如下:
1 | def sample(self, features, max_length=30): |