目标检测的backbone
ResNet
Deeper neural networks are more difficult to train.残差网络的提出,可以训练更深的网络。
A building block
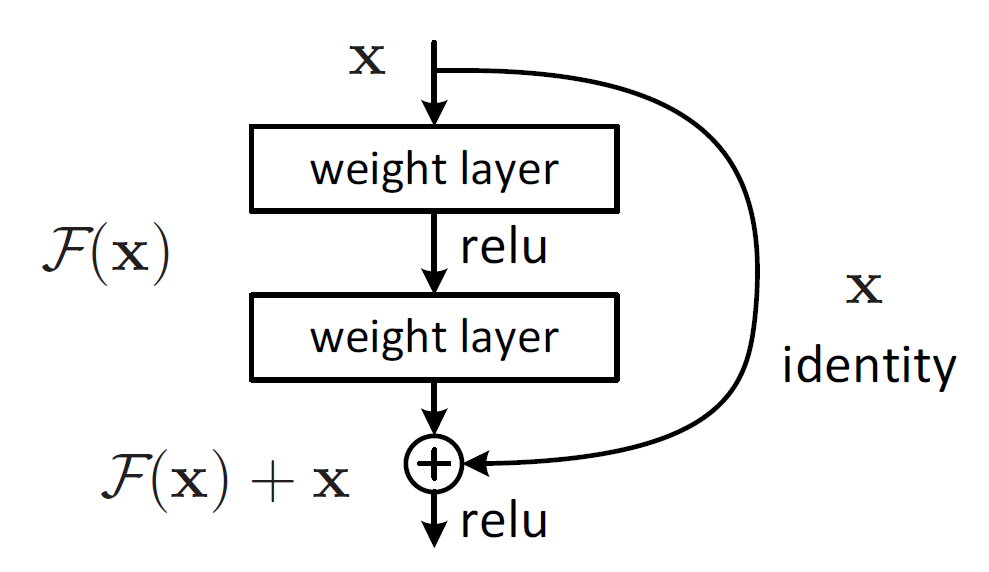
残差块使用了一种”shortcut connection”的链接方式,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解:
真正在使用的残差块并不是这么单一,文章中就提出了两种方式:
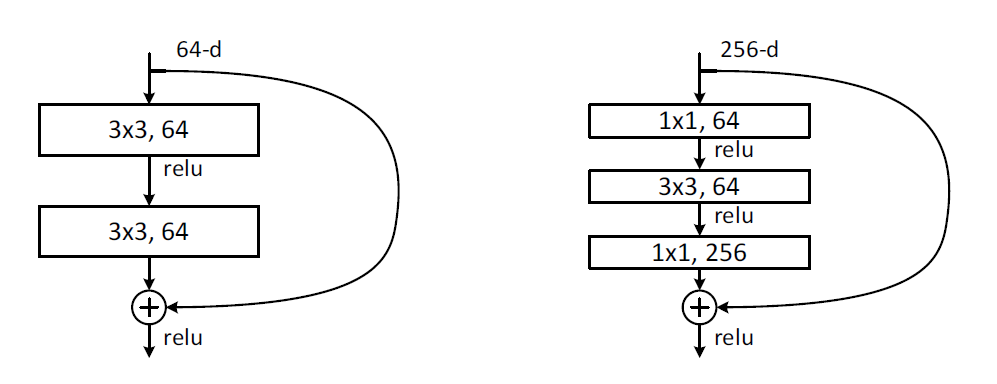
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图)。
其中右图又称为”bottleneck design“,目的就是为了降低参数的数目。
第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632;而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规building blocks,可以用于34层或者更少的网络中,而bottleneck design通常用于更深的如ResNet101这样的网络中,目的是减少计算和参数量。
我们看到残差块是通过一条 shortcut connection 保留低层网络学到的特征$\boldsymbol{x}$,和这几层新学的特征$F(\boldsymbol{x})$相加。这样理论上网络最差也不会比低层网络的效果差。
如果$F(\boldsymbol{x})$和$\boldsymbol{x}$维度不同的话,通过一个$W_s$进行线性的维度映射(mask-rcnn keras&tf实现中是用的一个ConvNet)。
ResNet50和ResNet101
下表一共列出了5种深度ResNet的architecture。所有的ResNet都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,之后的其他论文也会专门用这个称呼指代ResNet50或者101的每部分。
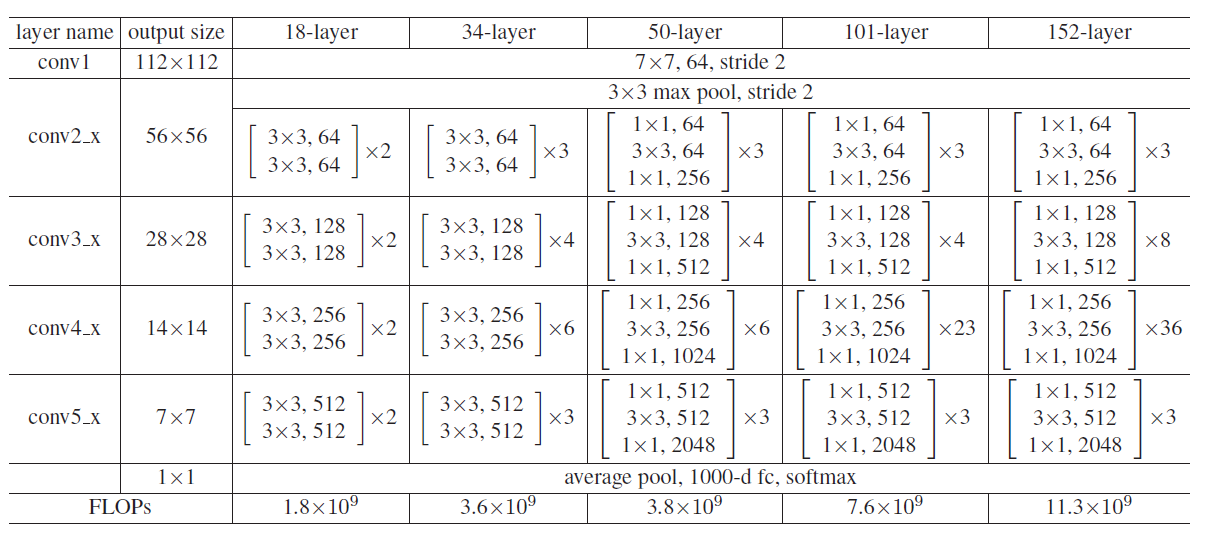
很多方法都建立在ResNet50或者ResNet101的基础上完成的。这里我们关注50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,相差17个block,也就是17 x 3 = 51层。
注:101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内;
ResNet50的keras实现:https://github.com/fchollet/deep-learning-models/blob/master/resnet50.py
FPN
FPN解决了什么问题
在以往的faster r-cnn进行目标检测的时候,roi都只作用在最后一层。这对于大目标的检测没有问题,但对于小目标的检测就会出现问题,因为随着卷积操作会缩小特征图的尺寸,小目标的语义信息到高层已经不存在了。卷积网络在较低层分辨率高,学习到了较多的细节信息;较高层分辨率低,学习到了较多的语义信息。
所以为了解决多尺度检测的问题,引入了特征金字塔网络。
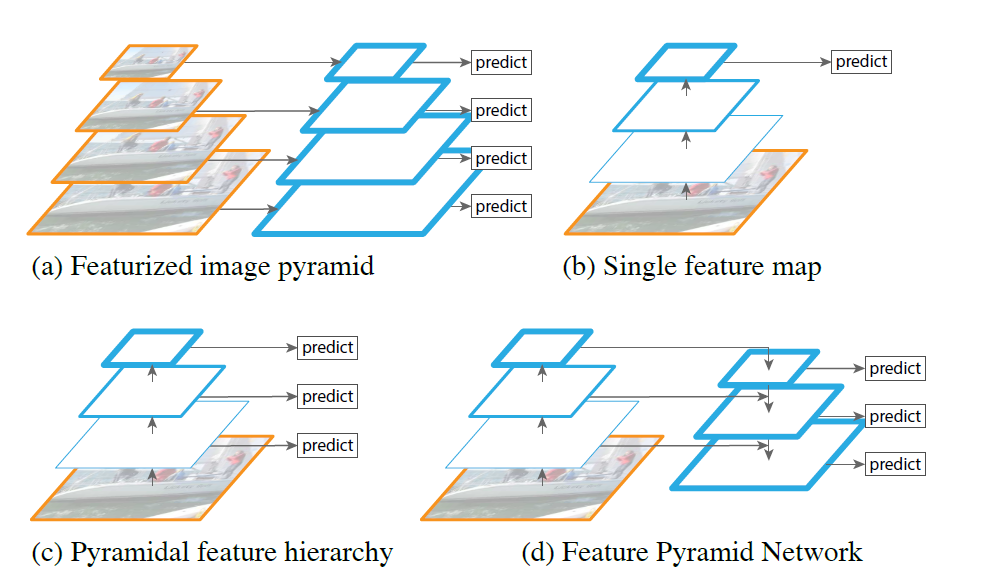
- 图(a)使用了图像金字塔来建立一个特征金字塔。通过不同尺度的图像训练得到不同尺度的特征。慢。
- 图(b)CNN
- 图(c)SSD较早尝试了使用CNN金字塔形的层级特征。理想情况下,SSD风格的金字塔 重利用了前向过程计算出的来自多层的多尺度特征图,因此这种形式是不消耗额外的资源的。但是SSD为了避免使用low-level的特征,放弃了浅层的feature map,而是从conv4_3开始建立金字塔,而且加入了一些新的层。因此SSD放弃了重利用更高分辨率的feature map,但是这些feature map对检测小目标非常重要。这就是SSD与FPN的区别。
- 图(d)FPN
如何工作
FPN为了自然地利用CNN层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔。所以FPN的结构设计了top-down结构和横向连接,以此融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
自下而上的路径
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为”same network stage”。对于每个stage选择最后一层的输出作为特征图的参考集。 这种选择是很自然的,因为每个阶段的最深层应该具有最强的特征。
具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。考虑到内存占用,没有将conv1包含在金字塔中。
自上而下的路径和横向连接
自上而下的路径(the top-down pathway )是如何去结合低层高分辨率的特征呢?方法就是,把更抽象,语义更强的高层特征图进行上取样,然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做应该主要是为了利用底层的定位细节信息。

上图显示连接细节。把高层特征做2倍上采样(最邻近上采样法,可以参考反卷积),然后将其和对应的前一层特征结合(前一层要经过1 1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1 1的卷积核来产生最粗略的特征图,最后,作者用3 3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。为了后面的应用能够在所有层级共享分类层,这里坐着固定了33卷积后的输出通道为d,这里设为256.因此所有额外的卷积层(比如P2)具有256通道输出。这些额外层没有用非线性。
{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相通的。
源码可参考mask r-cnn