多人检测:alphaPose
原文连接:RMPE: Regional Multi-Person Pose Estimation
现在单人姿态已经做的比较好了,但多人姿态估计任务还有待提升。
多人姿态估计的工作,大多分为两大类。一种是自上而下的方法:先检测人的bounding boxes,再进行单人的姿态估计;另一种是自下而上的方法:首先独立的检测所有的身体部位,然后在进行组装。
前者的关键在于如何产生高质量的人体检测框,后者的关键在于如何进行组装,尤其是当人们挨得很近的时候。作者认为自下而上的方法缺失了从全局姿势的角度去识别身体部位的能力。
本文提出的方法是一种自上而下的方法。大体思路,先使用faster r-cnn得到人体的bounding box,再用stacked hourglass network进行预测。其中细节在后文中进行阐述。
面临的问题
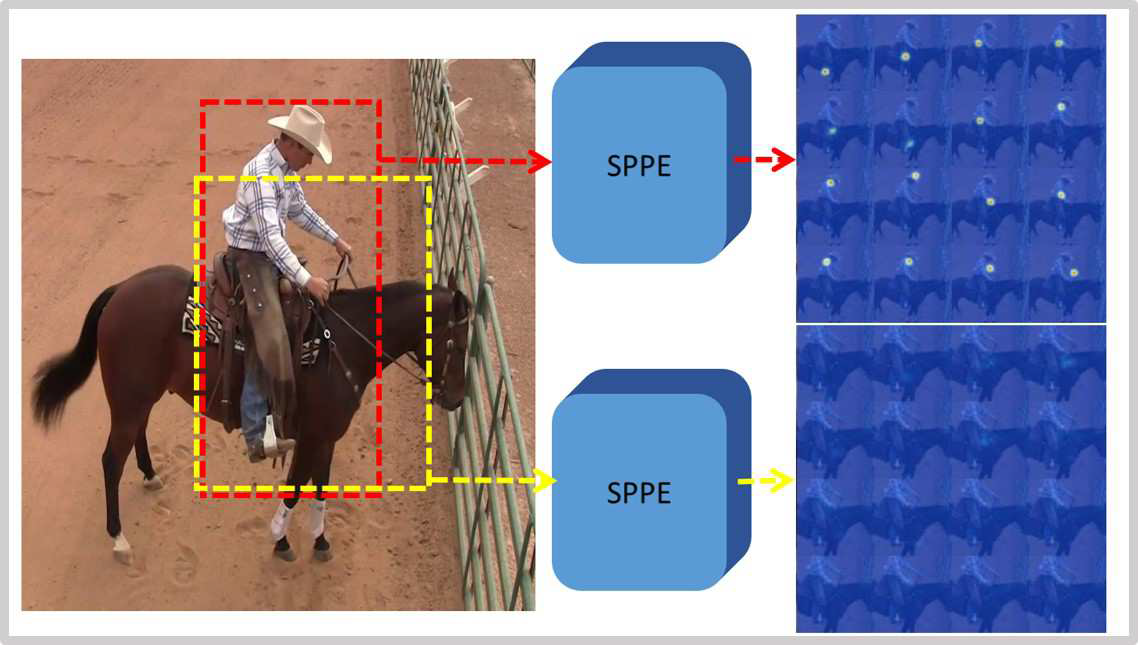
proposal人体检测框不准
单人检测的方法,对bounding box的准确度要求很高。而目标检测的方法,提出的bounding box往往不能完全框住一个人。例如下图,不同的检测框,使用stacked hourglass network(SPPE)进行检测,会产生非常大的误差,甚至不能检测。
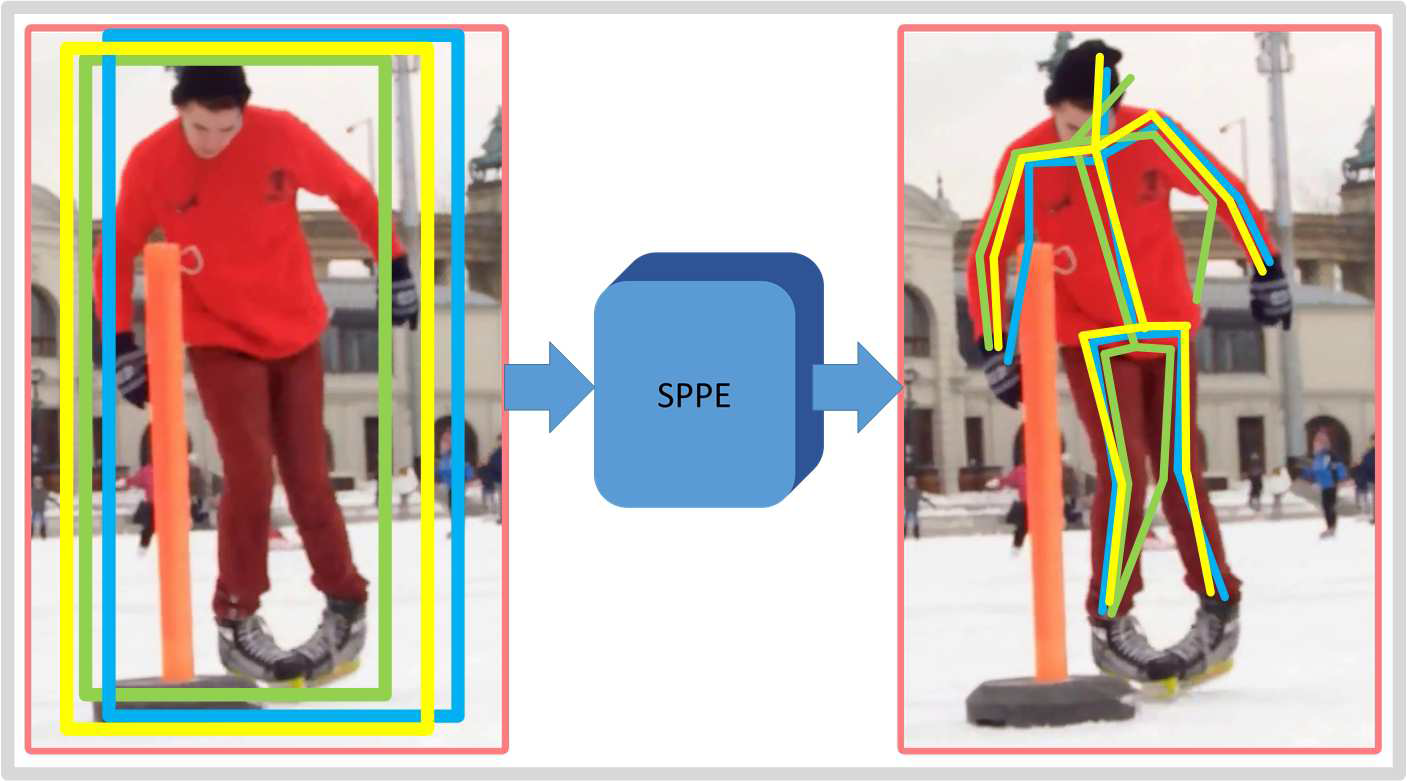
检测框冗余
如下图所示,左图是检测到多个重复的boxes(这个我在faster rcnn的proposal里还没有看到这么夸张的。。),右图是相应的关键点检测。毫无疑问,重复的框,得到重复的关键点。
alphaPose的解决办法
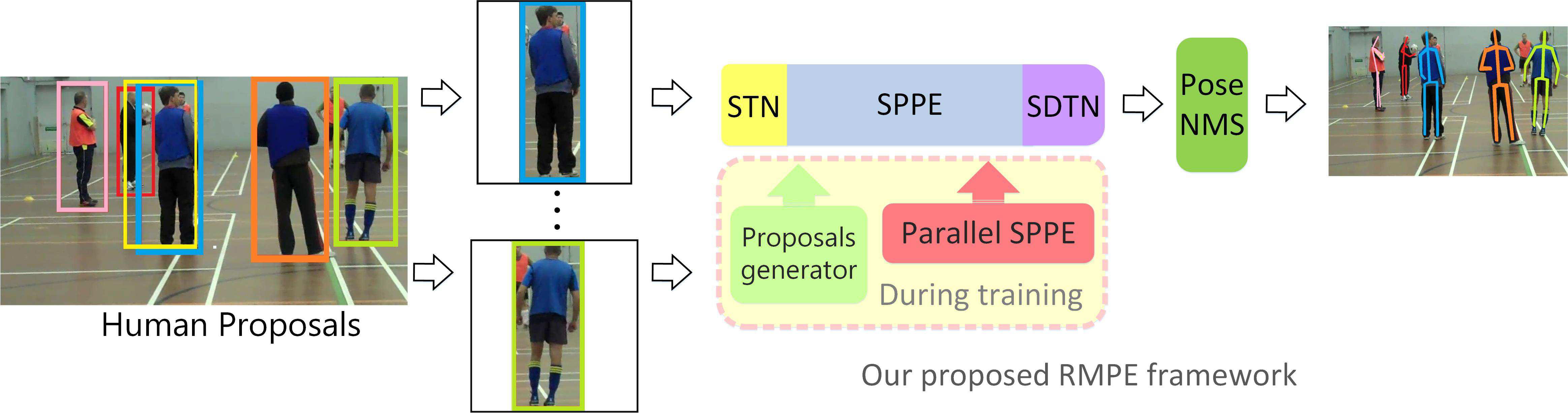
上图是alphapose的整体结构。通过faster r-cnn得到human proposals之后,使用一个Spatial Transformer Networks(STN)进行调整,理想化的目的是对检测框的一种矫正,实际中的作用是能够让预测出的关键点在图像的中央。STN对检测框矫正后,使用SPPE进行单人姿态估计,随后在使用STN的逆仿射变换,文中称为SDTN将预测的关键点位置还原到原图中的位置。
理想情况下,使用STN能一定程度消除检测框不准的影响,如何保证STN和SPPE各司其职,发挥其作用呢。
一种可能的方法是,在SPPE之后SDTN之前使用一个正则化损失,来保证关键点的位置在检测框中央。但是这样的话,因为损失由STN+SPPE的参数一起影响的,所以SPPE的学习会收到这种中心化的影响,就不能专注的进行姿态估计。(文中提到这种方法会降低模型的表现)
Parallel SPPE
alphapose提出了一个平行的SPPE结构,来帮助STN的仿射变换提取出好的特征。
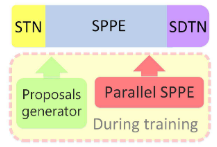
具体操作:平行的SPPE与原始的branch共享一个STN,但是SPPE的参数固定(大概固定在具有较好检测功能的参数值上就行了),不需要SDTN。
平行的SPPE专注于让检测到的姿势特征中心化,因为parallel SPPE的参数固定,所以只有STN的参数才对中心化损失产生影响。这一结构只在训练中使用,也就是说Parallel SPPE只是为了帮助STN能够更好的训练,完成它的任务。
Parametric Pose NMS
文中使用非极大值抑制来解决姿态冗余的问题(好像proposals冗余问题也是用的no-Maximum suppression)